~ハルシネーション抑制やマルチモーダルデータを扱う高性能LLMを開発~
KDDI株式会社
KDDIは2024年7月1日、国立研究開発法人情報通信研究機構(本部:東京都小金井市、理事長:徳田 英幸、以下 NICT)と大規模言語モデル(LLM)に関する共同研究(以下 本研究)を開始しました。
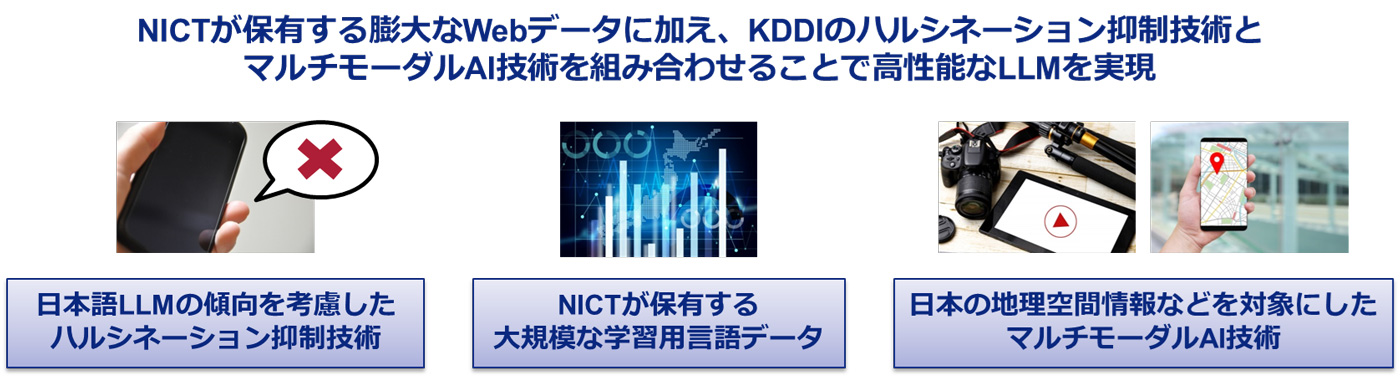
本研究では、NICTがこれまでに蓄積してきた600億件以上のWebページのデータなどと、KDDI総合研究所が開発してきた、生成AIが事実と異なる内容などを生成するハルシネーションを抑制する技術やマルチモーダルAI技術(![]() 注1)を活用します。これらを基に、LLMを活用する上で課題となるハルシネーションの抑制や、地図画像および付随する建物情報などのマルチモーダルデータの取り扱いを可能にする技術を研究開発します。
注1)を活用します。これらを基に、LLMを活用する上で課題となるハルシネーションの抑制や、地図画像および付随する建物情報などのマルチモーダルデータの取り扱いを可能にする技術を研究開発します。
なお、本研究は総務省・NICTが令和5年度補正予算を活用し推進する「我が国における大規模言語モデル(LLM)の開発力強化に向けたデータの整備・拡充及びリスク対応力強化」における共同研究の第1弾です(![]() 注2)。
注2)。
KDDIは、KDDI VISION 2030「『つなぐチカラ』を進化させ、誰もが思いを実現できる社会をつくる。」の実現に向け、NICTを始めとしたさまざまなパートナーと共に、日本独自の生成AI開発を加速させていきます。さらに、各産業・各業界のビジネスパートナーと共に、事業を通じた持続可能な社会の構築を進め、日本全体の活性化に貢献していきます。
詳細は別紙をご参照ください。
<別紙>
■背景
KDDIグループは、生成AI開発のための大規模計算基盤の整備を開始するとともに、オープンモデル活用型の日本語汎用LLMおよび領域特化型LLMの開発体制を整えてきました。またNICTは、これまでに蓄積してきた600億件以上のWebページのデータを活用し、LLMの事前学習に用いるデータの整備を進めてきました。また、並行して軽量な130億パラメータのLLMから日本語特化型では世界最大規模となる3,110億パラメータのLLMまで、1年あまりで合計17個のLLMの事前学習を完了させてきました。
■研究概要
LLMの利用にあたっては、事実と異なる内容や脈絡のない文章などが生成されるハルシネーションや、地図情報の活用が難しいことなどが課題になっています。
本研究では、NICTが長年蓄積した膨大なWebページのデータや、そこから作成したLLMの事前学習用データなどを活用し、共同研究を進めます。KDDIは、日本語汎用LLMの傾向に合わせたハルシネーション抑制技術の高度化や、地図画像および付随する建物情報などのマルチモーダルデータをLLMで取り扱う技術を、KDDI総合研究所のハルシネーション抑制技術やマルチモーダルAI技術を基に研究開発します。
これらの技術により、特定の目的のための対話システムや雑談システムにおける、LLMの信頼性向上につながります。また、LLMによる位置関係の把握などが可能になるため、例えば通信事業者のお客さま応対に適用することで、問題が発生している設備やエリアの迅速な把握が可能となり、通信品質の改善につながることが期待されます。
■各社の役割
- KDDI:ハルシネーション抑制技術およびマルチモーダルAI技術の高度化・評価
- NICT:LLM開発のための学習データの開発・提供、LLMの事前学習の実施およびその評価
(参考)
■これまでの取り組み
- 注1)テキスト、画像、音声、各種センサデータなどの複数種類のデータを統合的に利用し、総合判断を行うAI技術。
- 注2)国内AI開発力強化のため、学習用言語データの整備・拡充が進められている。本件は、総務省・NICTにおいて令和5年度補正予算を活用し、NICTが収集を続けてきたWebページのデータやそこから作成した学習用データなどを、民間企業や国の研究機関、大学などに共同研究を通じて提供するもの。




ダウンロード
関連記事
- ※この記事に記載された情報は、掲載日時点のものです。
商品・サービスの料金、サービス内容・仕様、お問い合わせ先などの情報は予告なしに変更されることがありますので、あらかじめご了承ください。